Instruct-Imagen generalizes to heterogeneous and complex image generation tasks.
This paper presents Instruct-Imagen, a model that tackles heterogeneous image generation tasks and generalizes across unseen tasks. We introduce multi-modal instruction for image generation, a task representation articulating a range of generation intents with precision. It uses natural language to amalgamate disparate modalities (e.g., text, edge, style, subject, etc.), such that abundant generation intents can be standardized in a uniform format.
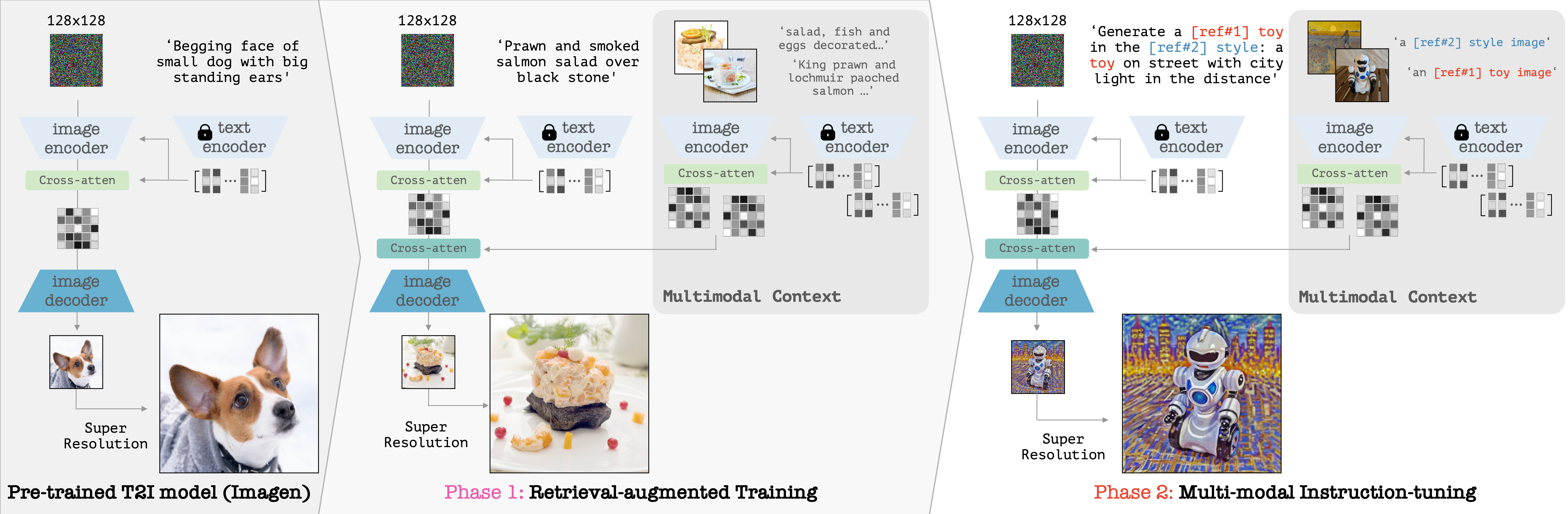
We then build the instruct-imagen by fine-tuning a pre-trained text-to-image diffusion model with a two-stage framework. First, we adapt the model using the retrieval-augmented training, to enhance model's capabilities to ground its generation on external multimodal context. Subsequently, we fine-tune the adapted model on diverse image generation tasks that requires vision-language understanding (e.g., subject-driven generation, etc.), each paired with a multi-modal instruction encapsulating the task's essence. Human evaluation on various image generation datasets reveals that instruct-imagen matches or surpasses prior task-specific models in-domain and demonstrates promising generalization to unseen and more complex tasks.
Instruct-Imagen extends a pre-trained text-to-image imagen model with two-stage fine-tuning
With a small number of additional parameters (10%), Instruct-Imagen can be trained to understand multi-modal instructions, without any descriminative training.
Instruct-Imagen exceeds in generating various in-domain tasks
Unlike some SoTA methods such as DreamBooth or StyleDrop, instruct-imagen do not require any test-time fine-tuning and can inference on the fly (~18.2 sec per example!)
More importantly, Instruct-Imagen zero-shot generalizes to compositional and more complex tasks
Without training on any data from the tasks below, instruct-imagen can produce very reasonable images w.r.t the complex multi-modal instruction.
Cite us using the following BibTex:
@article{hu2024instruct,
title={Instruct-Imagen: Image Generation with Multi-modal Instruction},
author={Hu, Hexiang and Chan, Kelvin and Su, Yu-Chuan and Chen, Wenhu
and Li, Yandong and Yang, Zhao and Ben, Xue and Gong, Boqing
and Cohen, William W and Chang, Ming-Wei and Jia, Xuhui},
journal={arXiv preprint arXiv:2401.01952},
year={2024},
}
Border Impact
Text-to-image generation models like Imagen and Stable Diffusion present ethical concerns, including social bias. Instruct-Imagen, using similar Web-scale datasets, faces these same issues. Instruct-Imagen's retrieval-augmented training and multi-modal instruction-tuning have notably enhanced image controllability and attribution. This control can be beneficial or harmful. A risk is using Instruct-Imagen for malicious activities, such as creating misleading images of people. Conversely, it offers advantages, like reducing image hallucination and improving relevance to user intent. It also benefits minority communities by effectively generating images of less-known landmarks, foods, and cultural artifacts, addressing the bias in AI systems. To mitigate public risks, we'll be cautious with code and API releases. Future work will focus on a responsible use framework, weighing the benefits of research transparency against the dangers of open access, ensuring safe and beneficial usage..
Special Thanks
We thank Zhiwei Deng, Jason Baldridge, Nando de Freitas for reviewing an early version of this paper in depth, with valuable comments and suggestions. Special thanks to Han Zhang for project idea discussion in the early stage of this project. We also thank Irina Blok for providing a style image used in our evaluation.
 Instruct-Imagen: Imagen Generation with Multi-modal Instruction
Instruct-Imagen: Imagen Generation with Multi-modal Instruction